



Az emberi gondolkodás plusszai: belső állapotok és többlépcsős gondolkodás
Amit a fentiekben összefoglaltunk, az megfelel egy közepesen fejlett emlősállat érzékelésének, tervezésének, döntéseinek, tanulásának és az azokban résztvevő visszacsatolásoknak. Az emberi agy evolúciója során azonban megjelent egy nagyon fontos új visszacsatolás a homloklebeny továbbfejlődése során.
 Az egyszerű elmék reaktívak, ha történik valami a környezetükben reagálnak. Ezzel szemben az emberek (és egyéb fejletteb tudatú állatok: elefántok, cetek, papagájok, varjúfélék, lábasfejűek) nem csak ingerekre reagálnak (stimulus-outcome) vagy egyszerű akciókat hajtanak végre (action-outcome), hanem:
Az egyszerű elmék reaktívak, ha történik valami a környezetükben reagálnak. Ezzel szemben az emberek (és egyéb fejletteb tudatú állatok: elefántok, cetek, papagájok, varjúfélék, lábasfejűek) nem csak ingerekre reagálnak (stimulus-outcome) vagy egyszerű akciókat hajtanak végre (action-outcome), hanem:
-egyrészt rendelkeznek bonyolult belső késztetésekkel (memóriában tárolt feladatok, hosszútávú célok), melyekre válaszokat dolgoznak ki belső késztetésre,
-másrészt, egy-egy ilyen megoldás kidolgozása több, egymás után kapcsolt tervezés-akció-kiértékelés-tanulás lépésből áll.
Egy agyunkban felmerült feladatra megszületett (rész)megoldás nem vált ki szükségszerűen azonnal egy mozgásban megnyilvánuló választ, hanem a megoldás és az abból fakadó szempontok, lehetőségek, visszakerülnek ugyanebbe a tervező rendszerbe és a megoldás tovább csiszolódik (az ingerre kapott válasz új ingerként ismét bekerül a rendszerbe). Számtalan körön keresztül, iteratív módon jutunk el a megoldásig, gondolkodunk, gondolatmeneteink vannak! Ugye, már megint a visszacsatolások amik új dolgokra tesznek képessé minket.
2025-ben az AI szakirodalom is felismerte az emberi gondolkodásnak ezt a fontos elemét, és CoT, azaz „Chain of Thought”, gondolati lánc, néven kezdte el alkalmazni az érvelések finomításához.
Ezek az extra körök, persze extra elemenként járulnak hozzá tudatosságunkhoz. Nem teljesen a jelenben és csak az ingerekbűvöletében élünk, hanem ÉNünk, tudatunk, céljainkat, gondolatmenetünket, emlékeinket is magában foglalja.
Hogyan is történik mindez?
Ne felejtsük, az agy idegsejtjei mintázatokkal dolgoznak. Számukra egy elvont feladat kiindulópontja ugyanúgy mintázat, mint egy külvilági inger. Ugyanígy, a megszületett megoldás idegsejt mintázata lehet egy mozgást kiváltó mintázat, de lehet egy olyan mintázat is, amely aztán kiindulópontként szolgál a következő tervezési-kiértékelési kör számára.
Elevenítsük fel az alap mozgástervezési kört:
- inger érkezik vagy megoldandó feladat merül fel
- az érzékelő ágon az agykérgi hierarchia ezt feldolgozza, vagy a homloklebeny értelmezi a feladatot
- ezután jönnek a tervezés hurkai (lásd feljebb), melynek során a kéreg-törzsdúcok/kisagy-talamusz körökben kiválasztásra kerül a legjobb megoldás
- a megoldást a motoros rendszer végrehajtja
- erre történik valami a környezetben, megkapjuk vagy nem kapjuk meg a büntetést vagy a jutalmat
- agyunk a jutalmazási rendszer segítségével kiértékeli a dolgokat és az RPE-nek megfelelő mennyiségű dopamin tájékoztatja az agyat arról, hogy most tanuljon vagy ne, boldog legyen vagy ne
Ezt a többlépéses gondolkodáshoz -anélkül, hogy a lényege és lépései megváltoznának – újra kell fogalmazni:
- megoldandó feladat merül fel, kerül elő a memóriából, vagy egy részmegoldásból indulunk ki
- a homloklebeny értelmezi a feladatot
- ezután jönnek a tervezés hurkai (lásd feljebb), melynek során a kéreg-törzsdúcok/kisagy-talamusz körökben kiválasztásra kerül a legjobb megoldás
- a megoldás nem kerül a motoros rendszerbe, hanem a kidolgozásától részben független homloklebeny terület (orbitofrontális kéreg, OFC) értékeli mennyire jó és az értékelést átadja
- a jutalmazási rendszernek, majd az RPE-nek megfelelő mennyiségű dopamin tájékoztatja az agyat arról, hogy most tanuljon vagy ne, boldog legyen vagy ne
- ha a megoldás közelített a célhoz visszakerülhet további csiszolásra (prelimbikus kéreg, PLC) és mellesleg a jutalmazási rendszer aktiválódik, hogy az rögzüljön, ha nem, visszalépünk és egy másik megoldást próbál agyunk kidolgozni.
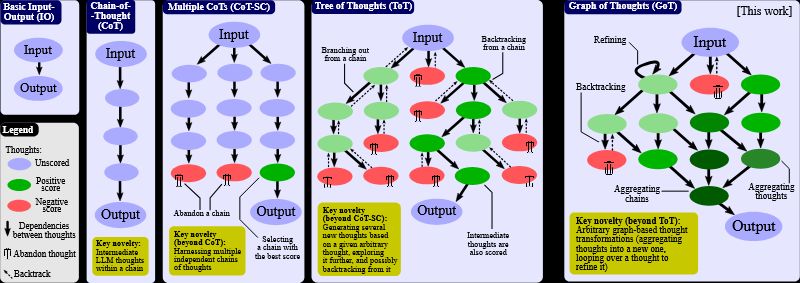
Ezt a visszalépést, újra próbálást, akár egyfajta Darwini természetes kiválasztódáshoz is hasonlíthatnánk. Ugyan nincs egyszerre sok „utód gondolat”, mindig egy szálon halad a továbblépés, de ugye itt is van mutáció (tovább gondolás) és szelekció (értékelés), mely több lépésben jobban túlélő (az feladat elvárásait teljesítő) megoldáshoz vezet.
Ami fontos még, hogy egy jól sikerült gondolat is képes a jutalmazási rendszert elindítani, azaz az agy saját magát is tudja jutalmazni. Ugye itt nem az érzékszervek felől jön a megerősítés, hanem a homloklebeny felől, hiszen azt kell felmérni, hogy a megoldás mennyire illeszkedik a lehetőségekhez, mennyire új, és hogy közelebb visz-e a célhoz. Ezután, mint korábban láttuk, nem csak megtanuljuk a helyes részlépést és több körön keresztül az érvelési láncot, hanem sikerélményünk is lesz és boldogok leszünk (a NAc közbenjárásával). Ha a soklépéses megoldás bevált és többször is használjuk a Nucleus Accumbenr (NAc) részvételével egylépésessé redukálódik. Itt is működik ugye a Hebb szabály, az első és az utolsó lépés együtt (időben közel) fordul elő, ezért az eredeti bemenet képes kiváltani a soklépcsősen kidolgozott választ.
 A másodfokú egyenlet megoldóképletének levezetésére már nem feltétlenül emlékszünk, de tudjuk használni. Egy bonyolult csomó megkötésénél eleinte még odafigyelünk arra, hogy a kötélnek hol kell átbújnia, de egy idő után már értelmezés nélkül, rutinból kötjük.
A másodfokú egyenlet megoldóképletének levezetésére már nem feltétlenül emlékszünk, de tudjuk használni. Egy bonyolult csomó megkötésénél eleinte még odafigyelünk arra, hogy a kötélnek hol kell átbújnia, de egy idő után már értelmezés nélkül, rutinból kötjük.
A jelenlegi AI-ból pont ezek a belső állapotok, késztetések és visszacsatolások hiányzanak. Többek között azért, mert a deep learningben használt back-propagation, visszaterjedéses tanulás nehezen tűri a visszacsatolásokat. De ebbe mélyebben itt most nem mennék bele.
Nyilván éveken belül ezeket is beépítk majd az AI fejlesztők akik, mint korábban neurobiológusoktól kérnek tanácsokat.
És akkor ezzel le is zárjuk a harmadik szintlépést. Jöhet a negyedik rész, mely a tudatosság dinamikájáról és annak következményeiről szól majd.
Szerző: Gulyás Attila